Gentle reader, if you subscribe to these pages it will not have escaped your notice that I have been absent for some little while. The good news is that I’ve been doing a lot more writing as part of my day job. The curse of doing what you enjoy for a living is that you seldom choose to do it in your time off as well, meaning less creative writing on this blog. That doesn’t mean I’ve been entirely negligent of my creative outputs however, and it is one of these which causes my prodigal return now.
A lot of my work nowadays revolves around unpicking the mystique around AI (artificial intelligence): the good, the bad, the ugly, and the totally over-hyped. Part of the reason I got into this area is due to my trustee work for Ellpha , a charity that uses the power of AI and data science to create a more gender-balanced world. When I took up my trustee role I felt it was very important that if I were going to comment and advise sensibly on bias in AI and other ethical issues around the space I had better understand the landscape. Through my research I’ve developed a special interest in how everyday people, not those working in technology, are impacted by AI and how we can all be informed consumers with the power to influence the mechanisms that are acting on us. You can read more about my thinking in this area and see a talk I delivered about it on InfoQ.
As an anthropologist my principal method for investigating things isn’t to read about them, it’s to try them for myself: there is nothing like the visceral experience of participant-observation for getting a real inside-out understanding of a subject. I’d been meaning for some time to try a ‘toy project’ to learn some practical techniques in AI. My goal really was to try and understand where data scientists identify (or don’t even notice) ethical decision points during a project so I could better grasp the ethical challenges data scientists face and perhaps gain more perspective on why we’re seeing some of the problems we are seeing with ethics in AI right now.
A combination of finding the right project, identifying the right methods for my skill level, and just plain old prioritising the idea among the many other investigative strings I’m constantly pulling meant that the idea sat low on my to-do list for quite some time. But finally a rainy Sunday afternoon arrived, perfect for playing around Google’s introductory AI courses, including the fairness in machine learning module and Colaboratory, Google’s in-browser interactive development environment that lets you try out machine learning techniques without the hassle of installing programs locally. After a couple hours playing around with tutorials I decided to start a project of my own from scratch.
My particular poison on this occasion was a neural network, a type of machine learning that uses input like text or images to generate a future prediction. Those DeepDream images you may have seen use a neural network, for instance. You can feed pretty much anything into a neural network and get an output that is similar to the input, you just need a large enough volume of data to train the network so the output doesn’t seem totally random. I was already familiar with and tickled by examples of AI Weirdness created by Janelle Shane, particularly her hilarious cookie names generated by a neural net and the accompanying illustrations. I too wanted to produce a whimsical yet recognisable product from a neural network. A little research told me that the right tool to use for my purpose would be a neural net package called textgenrnn which would run right in my Colaboratory browser window. But what data to use? As with most of my technology projects, the spark to finally act came from the arts.
A few days before my rainy afternoon I’d been to an all-male production of The Pirates of Penzance, one of Gilbert and Sullivan’s best-known comic operettas, at Wilton’s Music Hall. The production was an all-around triumph with a surprising amount of emotional depth, making the most of the characters’ unmet needs and the dignity of their longings as well as the comedic moments. Oh rapture! If I could cobble together a text file containing the complete works of Gilbert and Sullivan (or technically just Gilbert since it’s the librettos and not the music I’d be using) my neural net should have enough interesting and varied text to produce something suitably amusing.
Fortunately Project Gutenberg, a collection of over 58,000 free ebooks (mostly out of copyright works), offers the complete text of all Gilbert and Sullivan’s plays in an easily digestible text format–I wouldn’t even have to go around to the many G&S fan websites and put them together piece by piece.
A few hours and a couple of false starts later, GilbertBot5000 was running in fine form, producing this sample of practically stage-quality lyrics for my delight:
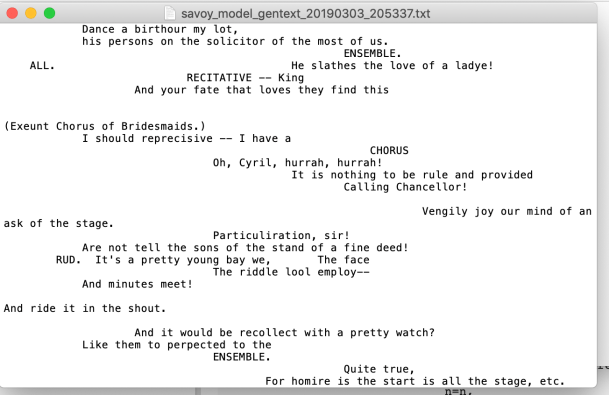
Hesitant though I am to find fault with my beloved GilbertBot, there are a few things I would like to do differently when I am more skilled. First I would classify the text so that only dialogue generates dialogue and stage instructions generate stage instructions, which might make it less prone to using ‘the stage’ as a setting for action (much as we all love a play-within-a-play.) If GilbertBot is truly meant to carry the banner of his namesake, his facility with language would also need vastly improved: rhyming would be a start. I think the true GilbertBot test would be getting it to understand metre–getting the stress of syllables right so the text could be set to music, as in Gilbert and Sullivan’s real operettas. I’m afraid such things are beyond my current prowess, alas.
I shall however be consoling myself with a second trip to the Pirates of Penzance next week. Even ethicists like to play at pirates sometimes!
